Here we will explore how to check billions of record from database without any lag or dely. Here we will see in the video, the traditional aspects along with their disadvantages.
Eventually we will explore Bloom filter. First let's take a look at some of the problems with traditional select() query.
Problems of SELECT queries in MySQL include
Lack of Indexes: Without proper indexing, queries may result in full table scans, slowing down performance.
Complex Joins: Multiple or inefficient joins, especially without indexing, can significantly increase query time.
Large Data Sets: Selecting large amounts of data without filtering can cause high memory and CPU usage.
Subqueries: Poorly optimized subqueries can be slow and may execute multiple times.
Locking Issues: Queries can cause table locks, leading to latency for other transactions.
Problems of Redis Cache include
Memory Limitations: Redis stores data in-memory, so it’s constrained by the available RAM. Storing large datasets or unoptimized structures can exhaust memory, causing latency spikes or crashes.
Network Latency: If Redis is not close to the application server, network latency can occur, slowing down read/write operations.
Single-Threaded Bottleneck: Redis primarily operates as a single-threaded process, which can become a bottleneck under high write/read loads.
Eviction Policy: Poorly configured eviction policies may lead to frequent cache misses or unintended data loss.
Persistence Overhead: When using Redis persistence (RDB/AOF), there can be performance overhead, especially during save operations or log rewrites.
Race Conditions: Improper management of concurrent read/write operations may lead to race conditions, affecting data integrity and consistency.
Latency During Failover: In a clustered setup, failover or master-slave replication can introduce latency during role changes or network partitions.
Bloom Filter
Bloom filters can help address several of the Redis cache problems by reducing unnecessary cache lookups and optimizing memory usage:
Memory Limitations: Bloom filters efficiently track whether a key might exist in the cache using minimal memory. They prevent unnecessary cache entries, optimizing RAM usage.
Network Latency: With Bloom filters, the application can check if a key might be present before querying Redis, minimizing network calls and reducing latency.
Single-Threaded Bottleneck: By filtering queries, fewer operations reach Redis, preventing overloads and alleviating the single-thread performance bottleneck.
Eviction Policy: Bloom filters help reduce cache pollution, ensuring that only valuable keys remain and enhancing the effectiveness of eviction policies.
Persistence Overhead: By limiting unnecessary data in Redis, Bloom filters reduce the persistence load and associated performance impact.
Race Conditions: They ensure a lower volume of read/write operations to the cache, reducing the chance of race conditions.
Latency During Failover: By filtering traffic to the cache, Bloom filters help minimize load and disruption during failover scenarios, ensuring faster recovery.
Using Bloom filters alongside Redis can significantly enhance performance, optimize memory, and minimize latency.
In this situation we are taking an example using GoLang. GoLang has bloom library, which facilities the work for you.
package main
import (
"fmt"
"github.com/bits-and-blooms/bloom/v3"
)
func main() {
// Initialize a Bloom Filter
filter := bloom.New(20*1000*1000, 5)
// Add a username to the Bloom Filter
filter.AddString("john_doe")
// Check if a username exists
exists := filter.TestString("john_doe")
fmt.Printf("Username 'john_doe' exists? %v\n", exists)
// Check for a non-existent username
exists = filter.TestString("jane_doe")
fmt.Printf("Username 'jane_doe' exists? %v\n", exists)
}
It will create below output
Username 'john_doe' exists? true
Username 'jane_doe' exists? false
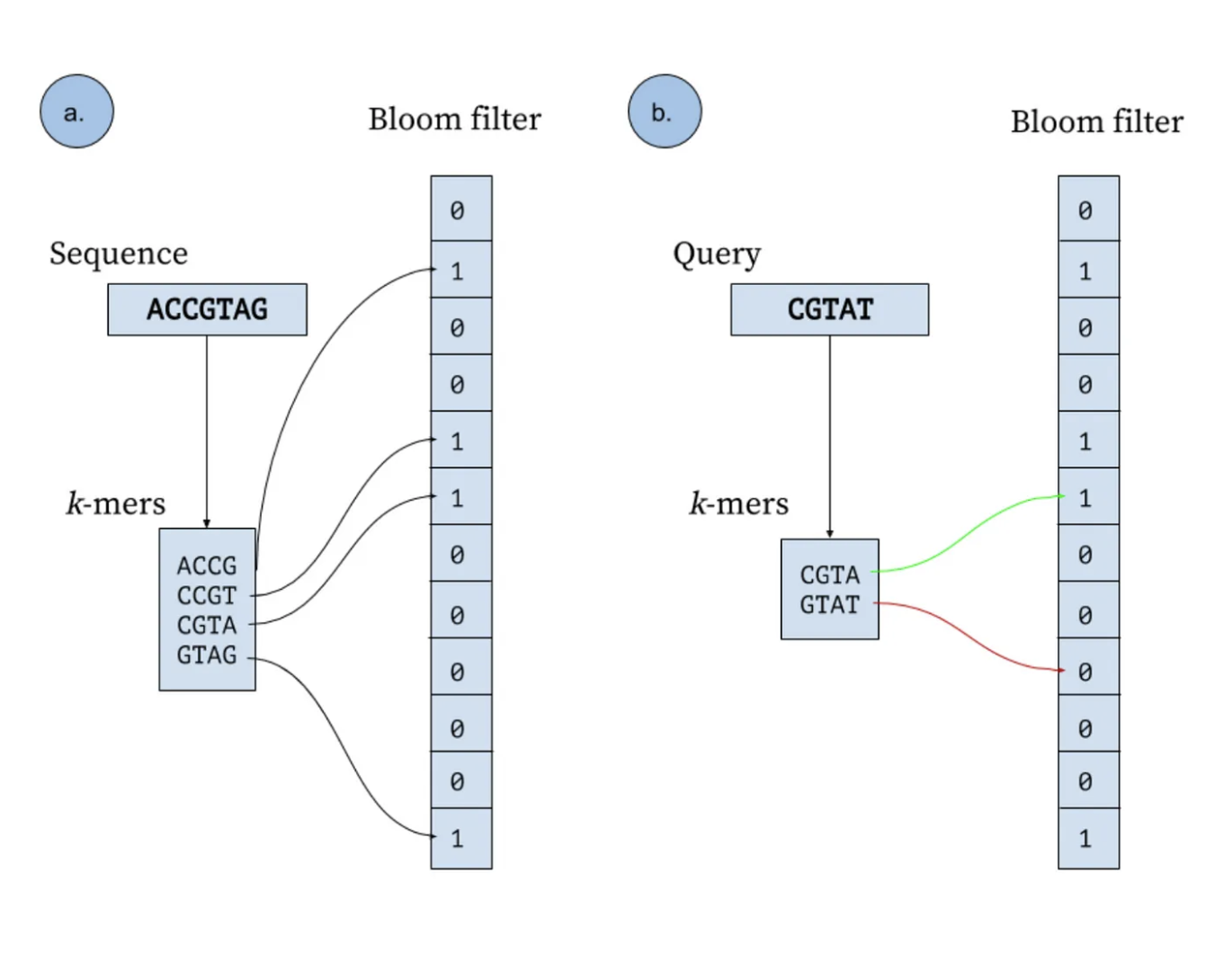
Let's see a visual representation of it